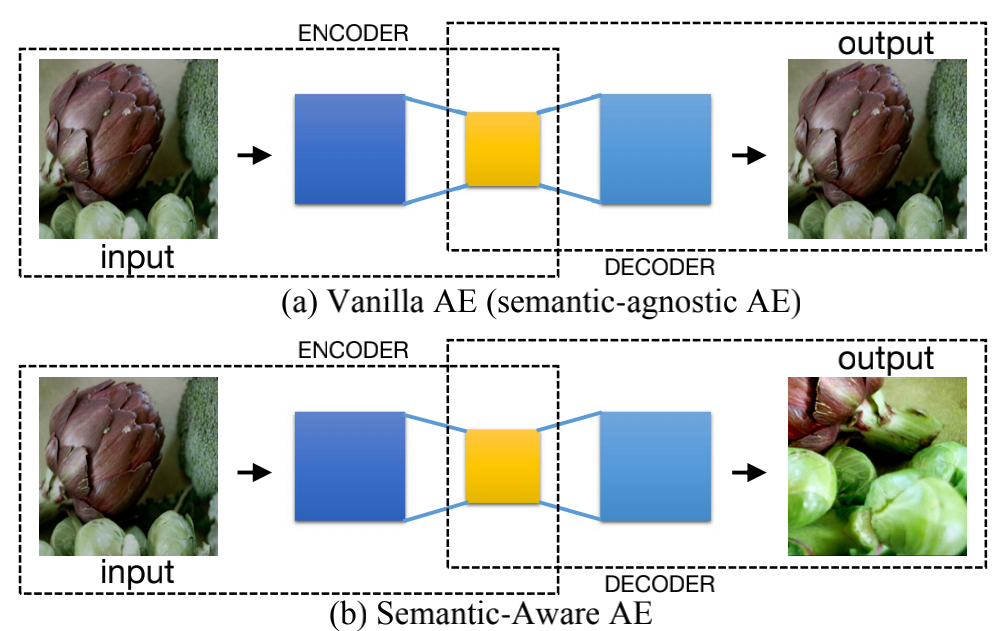
The resurgence of unsupervised learning can be attributed to the remarkable progress of self-supervised learning, which includes generative (G) and discriminative (D) models. In computer vision, the mainstream self-supervised learning algorithms are D models. However, designing a D model could be over-complicated; also, some studies hinted that a D model might not be as general and interpretable as a G model. In this paper, we switch from D models to G models using the classical auto-encoder (AE). Note that a vanilla G model was far less efficient than a D model in self-supervised computer vision tasks, as it wastes model capability on overfitting semantic-agnostic high-frequency details. Inspired by perceptual learning that could use cross-view learning to perceive concepts and semantics, we propose a novel AE that could learn semantic-aware representation via cross-view image reconstruction. We use one view of an image as the input and another view of the same image as the reconstruction target. This kind of AE has rarely been studied before, and the optimization is very difficult. To enhance learning ability and find a feasible solution, we propose a semantic aligner that uses geometric transformation knowledge to align the hidden code of AE to help optimization. These techniques significantly improve the representation learning ability of AE and make self-supervised learning with G models possible. Extensive experiments on many large-scale benchmarks (e.g., ImageNet, COCO 2017, and SYSU-30k) demonstrate the effectiveness of our methods.
@inproceedings{wang2022semantic,
title={Semantic-Aware Auto-Encoders for Self-Supervised Representation Learning},
author={Wang, Guangrun and Tang, Yansong and Lin, Liang and Torr, Philip HS},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={9664--9675},
year={2022}
}