ViT和MLP虽然取得了不错的进展,但是训练这两样东西,若要取得与CNN匹配有性能,需要更多的数据(如JFT-300 or imagenet-21k),更强的正则化。甚至初化始和学习率都影响很大。而相反,CNN的学习则相对很简单。
这篇文章从loss进行分析,想提高ViT和MLP训练时的效率,以及测试时它们的泛化性。
通过可视化发现,这些模型容易陷入尖锐的局部最优。利用最近的尖锐敏感性优化器,通过鼓励平滑性,可以大大提高它们的性能(在监督学习任务,对抗任务,对比学习任务,以及迁移任务中)。例如,在imagenet中可以提高vit的性能5.3%,在mlp中可提高11个点。不像以前的vit和mlp,本文不需要额外的数据集(jft-300 or imagenet-21k)来预训练,也不需要更强的augmentation。本文方法的attention maps也更加优美。
由于缺少卷积的inductive bias(这个词就是一种高雅的用法,说有意思也有意思,说没意思也没意思,大约相当于是如果你不知道怎么表达,就用这个高深莫测的词好了,卷积中的localilaty/平移不变性等所带来的神奇且难以理解的性质称为inductive bias),vit如果没有额外的数据预处理,性能会比imagenet低很多。但是加上大规模的预训练+强的data augmentation+更Tricky的超参数,vit会达到resnet相仿的性能。而计算资源消耗自然也就变大了。
既然如此,vit和resnet对比就迷幻一般了。
这篇文章用了一种优雅的优化器,在不需要额外大规模数据预训练(jft-300 or imagenet-21k)的情况下,使得vit的精度高于resnet,且使得mlp约等于resnet。(注:resnet用上这种新的优化器性能提升并没有vit和mlp大)。
作者首先经过可视化loss,发现vit和mlp会收敛到一个非常尖的局部最优。同时,loss的海森矩阵可以看出,从后往回bp的时候,最开始的层的次对角海森矩阵有最大的特征值。第二,mlp会比vit的training loss更低,也就是更容易更拟合。第三,vit和mlp的迁移能力更差。
这篇文章认为,一阶的优化器(如sgd, adam)只会追求最小化训练误差,没有考虑高阶信息(例如平滑性和泛化性),所以才会导致vit和mlp的这些问题。
基于以上分析,作者想到用“尖锐敏感的”优化器(SAM)来平滑loss。SAM是google research发表在iclr 2021上(https://openreview.net/pdf?id=6Tm1mposlrM)的一篇文章。其代码已经开源(https://github.com/google-research/sam)。(The above study and reasoning lead us to the recently proposed sharpness-aware minimizer (SAM) [23] that explicitly smooths the loss geometry during model training. )
SAM这种算法,会平滑邻居的loss,而不只关注某个点。(SAM strives to find a solution whose entire neighborhood has low losses rather than focus on any singleton point.)
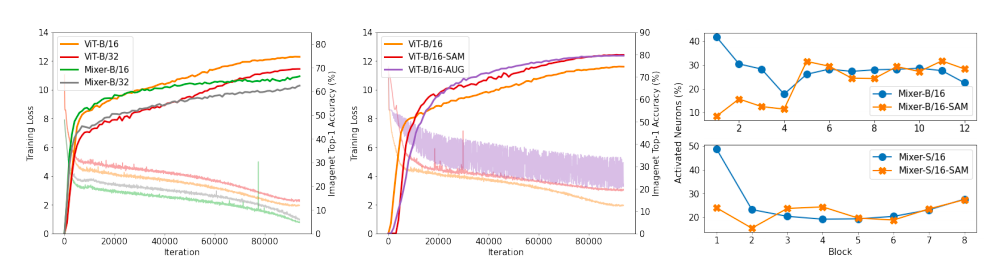
这篇文章还有一些厉害的发现。一是:用SAM来优化,会使得海森矩阵的特征值会更加稀疏,层越低,这个现象越明显。而且权重的范数会增加,这说明普通的l2 weight decay可能不太适用。用进一步改进的空间。(By analyzing some intrinsic model properties, we find the models after SAM reduce the Hessian eigenvalues by activating sparser neurons (on ImageNet), especially in the first few layers. The weight norms increase, implying the commonly used weight decay may not be an effective regularization alone.)
二是:vit被激活的神经元比较稀疏,说明vit有进一步减枝的可能。(注:由于vit相当于一个动态网络,那么稀疏的位置可能是动态变化的,所以,要想实现实际上加速的减枝,也许并没有作者所想的那么简单)(A side observation is that, unlike ResNets and MLP-Mixers, ViTs have extremely sparse active neurons (less than 5% for most layers), revealing the redundancy of input image patches and the capacity for network pruning.)
一种广泛的认识是,如果损失函数收敛到一个平常的区域,泛化性会好。如果收敛到尖锐的区域,则泛化性不好。为此,这篇文章画了一个loss的收敛情况。可以发现vit和mlp收到到很尖的区域。(It has been extensively studied that the convergence to a flat region whose curvature is small benefits the generalization of neural networks [10, 13, 29, 30, 33, 48, 64]. Following [36], we plot the loss landscapes at convergence when ResNets, ViTs, and MLP-Mixers are trained from scratch on ImageNet with the basic Inceptionstyle preprocessing [51] (see Appendices for details). As shown in Figures 1(a) to 1(c), ViTs and MLP-Mixers converge to much sharper regions than ResNets)
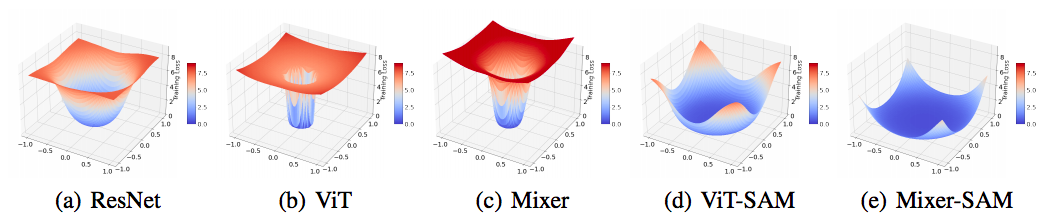
具体的,这个尖锐/平滑程度可以用海森特征值来刻画。作者算了一下,vit和mlp的海森特征值确实很大。
还可以看出来,vit和mlp的泛化能力较差。甚至,mlp比vit的泛化性更差。
为此,作者提出怎样的改进呢?
SAM优化器:最小最大化: \min_w \max_{\epsilon 小于 很小的值\ro} loss(w+\epsilon)。其意思是,在领域内,最大的loss必须最小化。但是这个最小最大化计算比较麻烦。所以采用一阶近似。先算\epsilon = \ro* loss关于w的梯度/loss关于w的梯度的二范数。因此,这个SAM优化器是真是简单有效。(Intuitively, SAM [23] seeks to find the parameter w whose entire neighbours have low training loss Ltrain by formulating a minimax objective)。
在鲁棒性方面,也公布了实验结果。值得注意的是,这里采用普通扰动来进行鲁棒性测试,而没有用对抗攻击来进行测试。(We also evaluate the models’ robustness using ImageNet-R [28] and ImageNetC [26] and find even bigger impacts of the smoothed loss landscapes. On ImageNet-C, which corrupts images by noise, bad weather, blur, etc., we report the average accuracy against 19 corruptions across five severity. As shown in Tables 1 and 2, the accuracies of ViT-B/16 and Mixer-B/16 increase by 9.9% and 15.0%, respectively, after SAM smooths their converged local regions.)
作者也用了SAM在“有监督”对比学习上,得到了显著的提升。(We couple SAM with the supervised contrastive learning [31] for 350 epoch)。( improving the ImageNet top-1 accuracy of ViT-S/16 from 77.0% to 78.1%, and ViT-B/16 from 77.4% to 80.0%.)
有研究表明,对抗训练可以提高损失函数的平常性。有意思。(Moreover, similar to SAM, Shafahi et al. [46] suggest that adversarial training can flatten and smooth the loss landscape)
总而言之,SAM对过拟合抑制,对泛化性的提交很有帮助。很让人有所启发。对我以往的工作有很多rethinking.
-----------------------------------
大家好,我来自fast lab。我开始不定时公开写作。这些写作主要通过两个渠道公布:一是FAST LAB官方网站;一是印象识堂(微信可访问)。欢迎大家订阅。谢谢!
FAST Lab的官方网址为:https://wanggrun.github.io/projects/fast
除此外,还可以关注我的小伙伴王广润:https://wanggrun.github.io/
王广聪: https://wanggcong.github.io/
石阳:https://www.linkedin.com/in/%E9%98%B3-%E7%9F%B3-381b521a4/
有时候这些网站打不开,请耐心多点几次。
多谢大家关注。